(苹果多开软件)学计算机的要点是什么?如何理解计算机软件
作为一个计算机人,我也面试过很多毕业生。我要讲的是计算机思维和对整个计算机的理解。随着计算机领域的发展,语言和框架层出不穷,但计算机的思维和底层是不变的。我来说说我对计算机的理解。希望你能通过这篇文章建立计算机思维。底层不难,架构不深刻。希望能给你一些思考和帮助。
导读:《大学》里有一句话叫‘凡事有终,皆有始’。如果你知道你做了什么,你会走捷径。你什么意思?万物皆有根有枝,万物皆有始有终。自始至终知道这个道理,就接近了事物发展的规律。那么,如果我们思考计算机是否有一致的规则,答案是肯定的。本文将通过计算机系统底层的一些书籍(组成原理、架构、汇编原理、汇编语言、intel开发手册、CSAPP、C++等)帮助我们正确高效地掌握计算机思维。).
易经有云,‘易太极,太极出两仪’。据了解,所谓太极,就是解释宇宙从无穷到太极的过程,甚至是万物的化生。电脑也不例外,体验是从零开始的。1936年艾伦的信吗?图灵提出了抽象计算模型,将人的数学运算过程抽象出来,一个虚拟机代替人类进行数学运算。我们称之为图灵机。直到冯·诺依曼提出计算机体系结构,从现在开始,无论是最原始的还是最先进的计算机,都还在使用冯·诺依曼系统最初设计的计算机体系结构。
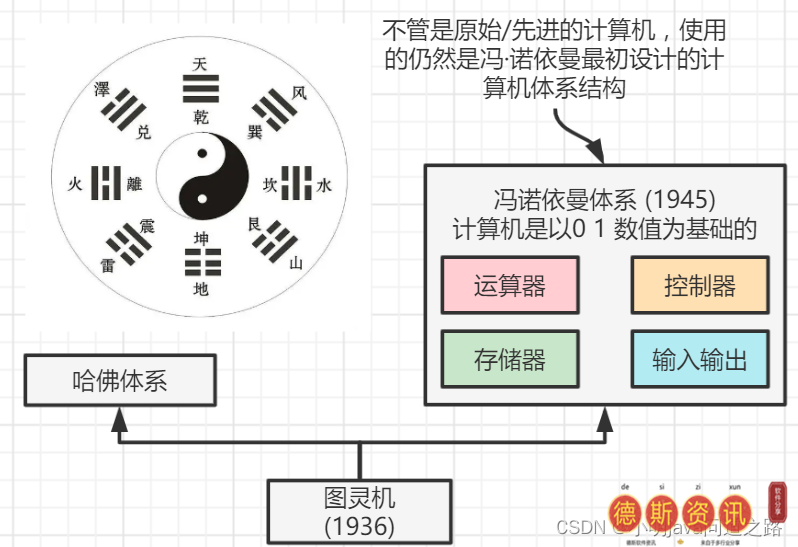
世界之初,太极生出两个仪器——从图灵机到冯诺依曼系统,再到冯诺依曼系统引出计算机架构。我们翻开《计算机架构的本质》这本书,描述了这个模块要了解数字逻辑(电压、晶体管等。),处理器、操作数和指令的基本原理,以及大量描述CPU、内存和总线等的篇幅。,所以我们的总结是冯。
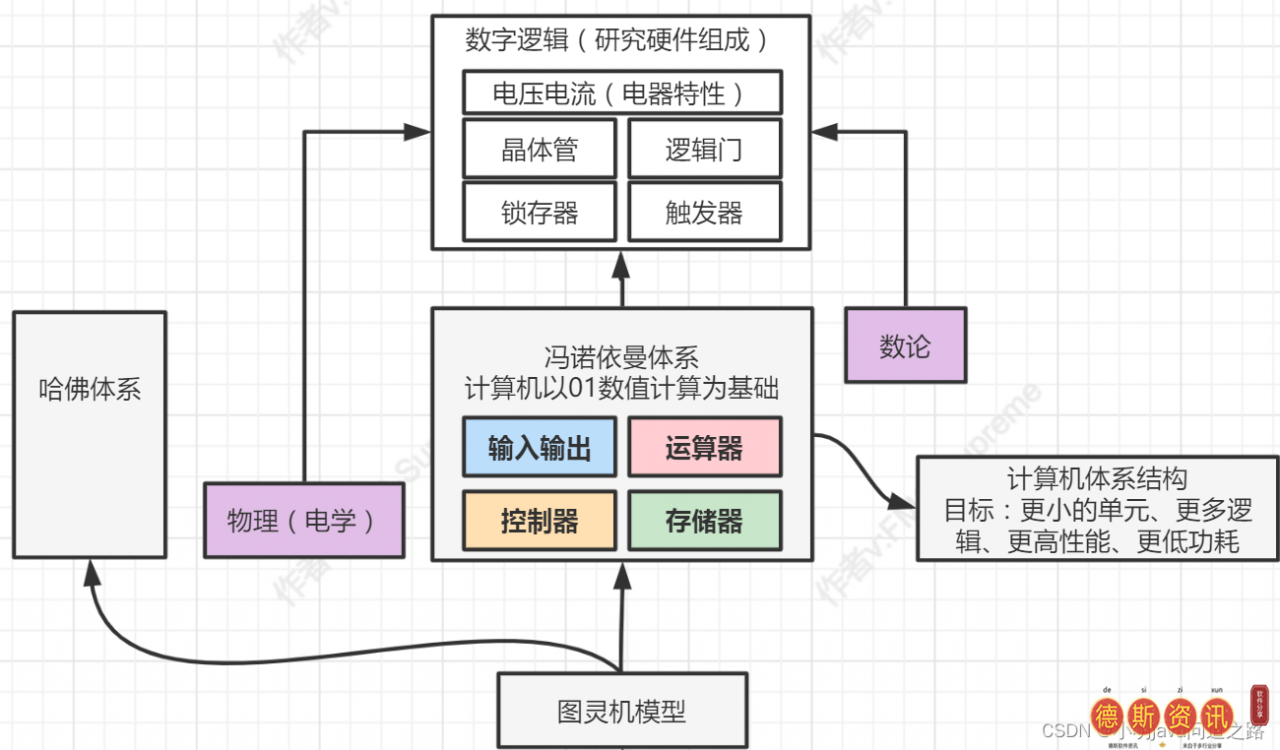
二生三,三生万物——冯·诺依曼系统与计算机系统架构。既然这样,我们现在就来看看计算机的组成,也就是计算机的宏观观。当我们打开计算机时,我们可以测试外围设备(I/O ),如键盘和鼠标。计算机内部是CPU(算术单元+控制器)、内存和磁盘(内存);微观上,从CPU内部来看,有几个模块:寄存器(MU)、主存、运算器(AU)、控制单元(CU)。顾名思义,这些模块是寄存器=内存,主存=输入/输出(因为需要和CPU外部交互),运算器=运算器,控制单元=控制器。
现代计算机的构成在这里,我们只理解计算机与CPU和冯诺依曼系统的关系。如果很难理解,我们可以换个角度。在我们的软件开发中,MVC架构,视图=输入/输出,控制器=运算器+控制器,模型=内存,能否理解冯诺依曼系统这个神器?
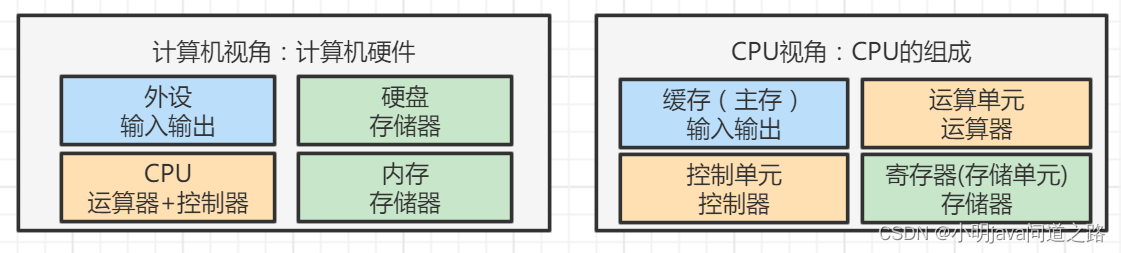
冯诺依曼系统与现代计算机和CPU的关系。至此,我们对计算机的整个底层有了初步的了解,知道CPU是计算机的核心(运算+控制),因为我们还没有深入到CPU(寄存器)、内存(数据内存、指令内存)等等。
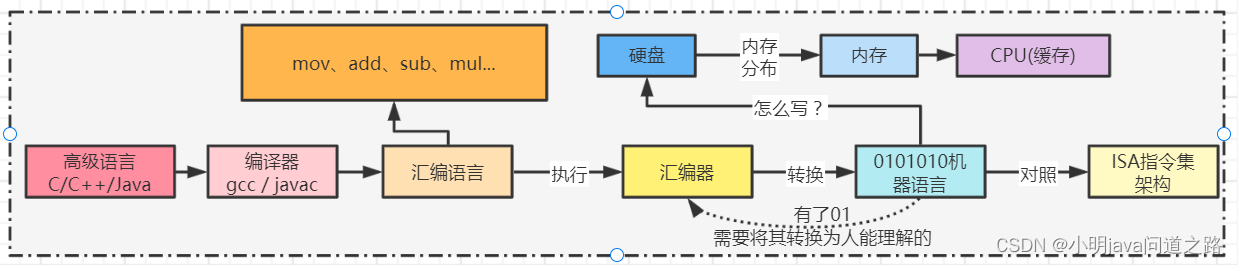
万事皆有终,万物皆有始。作为程序员,仅仅有底层逻辑是不够的,还要建立一个完整的从编译到执行的代码,也就是知道顺序。我们写的代码是如何操作上述硬件的?我们知道按照冯·诺依曼的体系,计算机只能识别0 1的代码,比如0000101,所以我们开始往上推。人类是不可能写出这个东西的。人类只需要对应0101的代码就可以了,但是不管是熟悉C语言还是Java,都不能直接把它变成0101的代码。那么中间一定是有什么东西做了一系列步骤把高级语言转换成机器语言(编译器->编译器)。
于是出现了ISA汇编指令集,在《计算机组成原理》中有详细论述。这里我们理解的是驱动和控制CPU的代码被封装成一个特定的指令集,由CPU厂商开发用来操作控制单元,将存储单元中的数据放入计算单元,并将计算结果返回给存储单元。
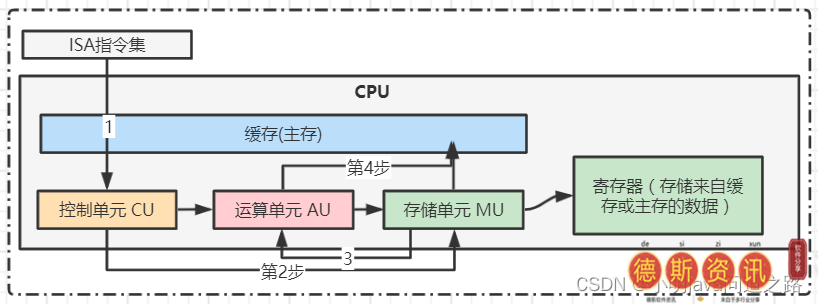
ISA操作CPU的进程。用汇编指令集,比如Java,PyThon,Go语言等。,我们还是不能直接操作ISA指令集。我们还需要一个能把左右语言编译成统一汇编语言(编译器)然后调用汇编代码的过程。把高级语言翻译成汇编语言或者机器语言的过程就是“编译原理”,然后汇编语言操作CPU控制其他硬件完成运算(操作CPU的控制单元,控制存储单元,运算单元操作缓存的数据)。
编译原理总结:到目前为止,我们得到了一个通用的所有语言的编译运行模型和计算机系统模型,简单的构造了ISA汇编指令集和汇编原理的理解。
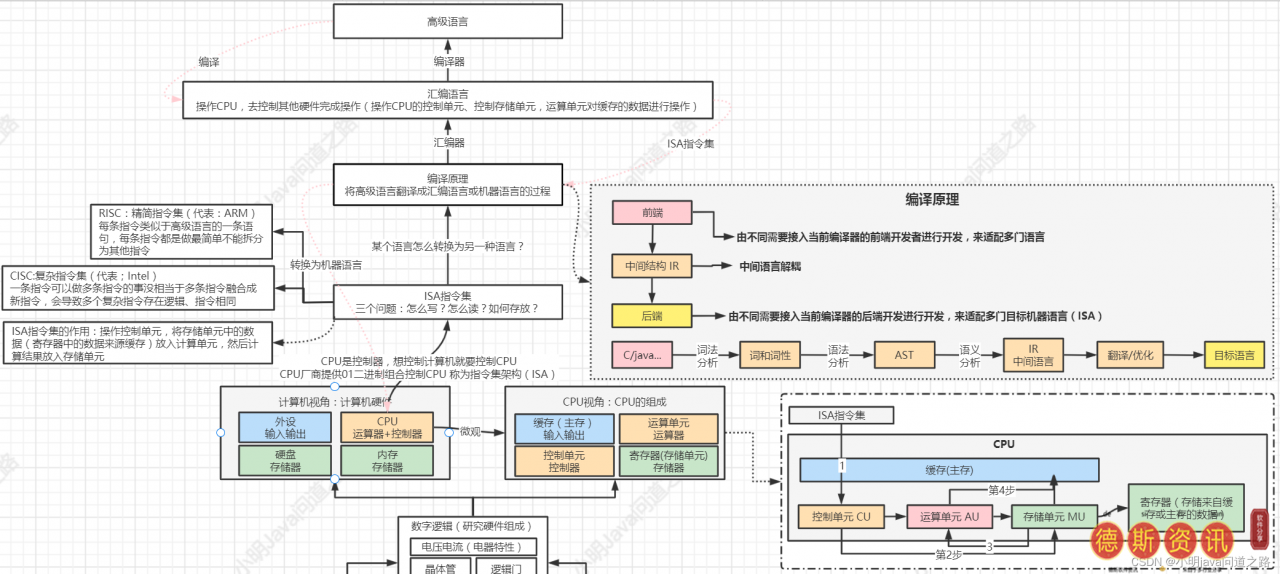
从代码到硬件,君子之道,走远了就自卑;往高处走,就会自卑。中庸之道中‘君子之道,远则自卑’,翻译过来就是君子中庸之道。就好像你要从很远的地方开始,就好像你要从很高的地方开始。经过以上两个讲座,我们知道了计算机的架构和代码编译的过程,但它们只是最简单的理解。现在我们开始攀登!
一、第一成就是什么?-计算机组成原理-ISA和CPU处理指令原理
说到控制电脑,我们需要控制CPU,而ISA操作CPU,从而操作其他一切。ISA是一个集合,所以肯定有多个内容。怎么做才能控制CPU?所以会有很多机器指令->:我怎么知道谁是谁?-& gt;所以机器码是基于CPU厂商给定的ISA,汇编器可以根据这个规则把01放到规则指定的位置。其实指令再神奇,数据毕竟是代码,需要容器来操作,需要内存来存储。CPU内存型号如下。
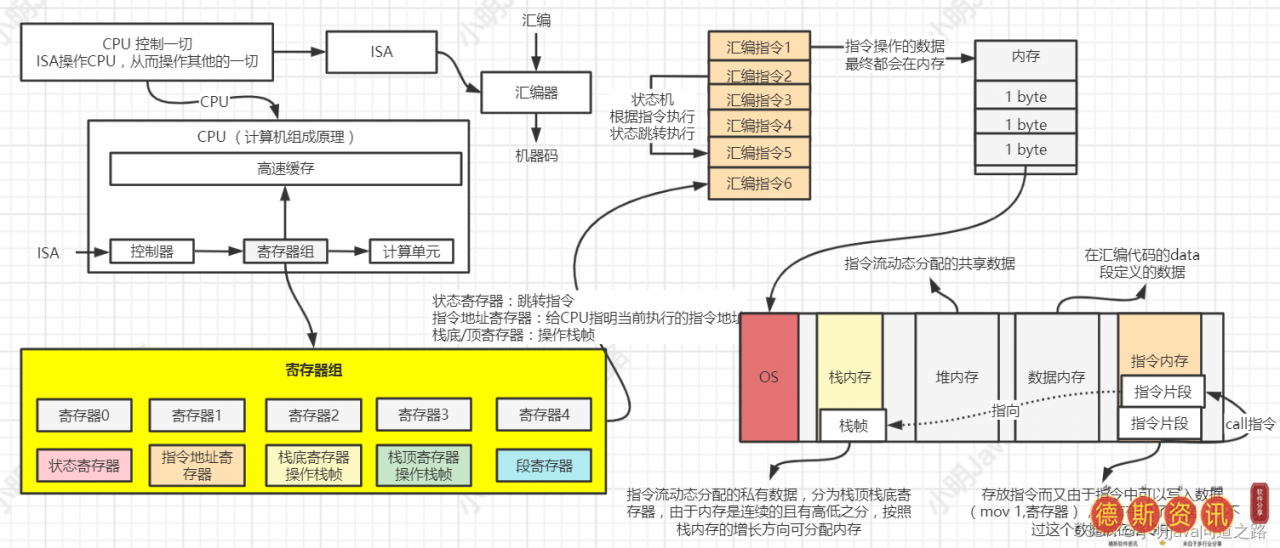
CPU内存模型指令所操作的数据最终都会在内存中,所以按照函数来切割内存存储区域就足够了:指令段的私有数据(栈)+指令段的共享数据(堆)->;可能不止一条指令,也就是说我可以调用多条指令-->:(stack)数据结构来表示这种存储关系。其中,指令流动态分配的私有数据被分为栈顶和栈底寄存器。因为内存是连续的,有高低级别,所以可以根据堆栈内存的增长方向来分配内存。指令流动态分配的共享数据称为堆内存。中定义的数据。汇编代码的数据段是数据存储器。指令存储器存储指令,由于数据(mov 1,寄存器)可以写入指令中,所以它再次存储数据,但这些数据是嵌入指令中的。
说了这么多,我想告诉读者,每个指令流都有自己的堆栈帧,堆栈帧保存着当前指令流操作的数据。当单元指令用于传输指令流时。只有最后一个堆栈帧的底部需要保存。所以在我们的程序中,栈内存可以理解为多个指令流的私有数据;堆内存是多个指令流共享的数据(动态数据);代码段内存是存储程序的指令流;内存是程序数据(编译时存在的数据静态数据)的存储。
可以看出,底层CPU、OS和JVM的内存模型是密切相关的。在这里,初级组件对内存模型、CPU和寄存器的了解比这更多。作者会在后续博文中详细介绍寄存器、缓存、intel手册等等。
二、谁能做到极亮极暗?-重新探索编译原理和汇编语言。
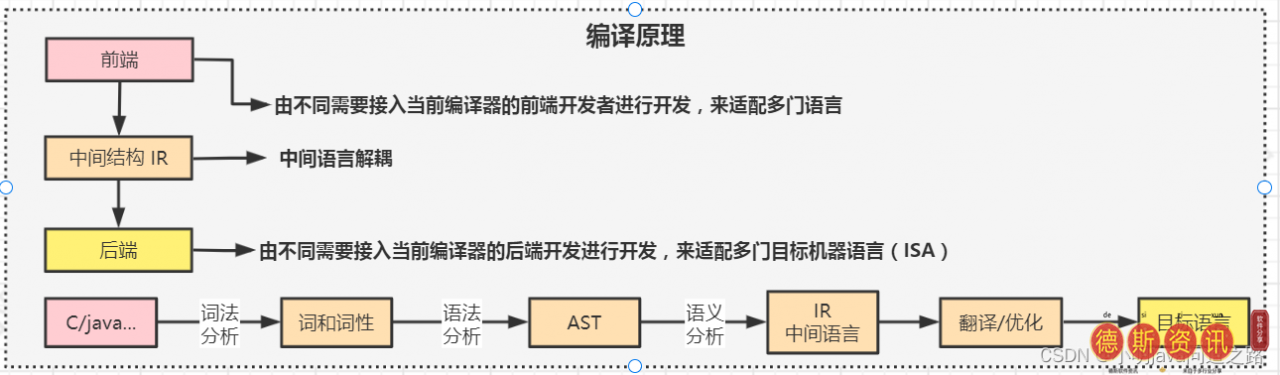
上面说的编译原理就是把高级语言翻译成汇编语言或者机器语言的过程。编译过程有一个三明治(三层)架构——前端、中间结构和后端。前端由不同的前端开发者开发,他们需要访问当前的编译器来适应多种语言。中间结构会产生一个叫做IR的中间语言解耦,后端由不同的后端开发者开发,他们需要访问当前的编译器来适应多种目标机器语言(ISAs)。中间细节类似于我们做英语翻译,分析语言的语法和语义,生成中间语言,最后转换成目标语言。可以参考java语言的编译流程,Java源代码->:用javac指令编译成字节码,这个字节码相当于IR中间语言。这里JIT (just-in-time compiler)实现了编译原理的前端和后端,但是在内存中动态编译语言;用一种语言(IR)解释其他语言,执行逻辑是解释器;编译器是一套完整的逻辑,有前端和后端,把一种语言(源语言)编译成目标语言。
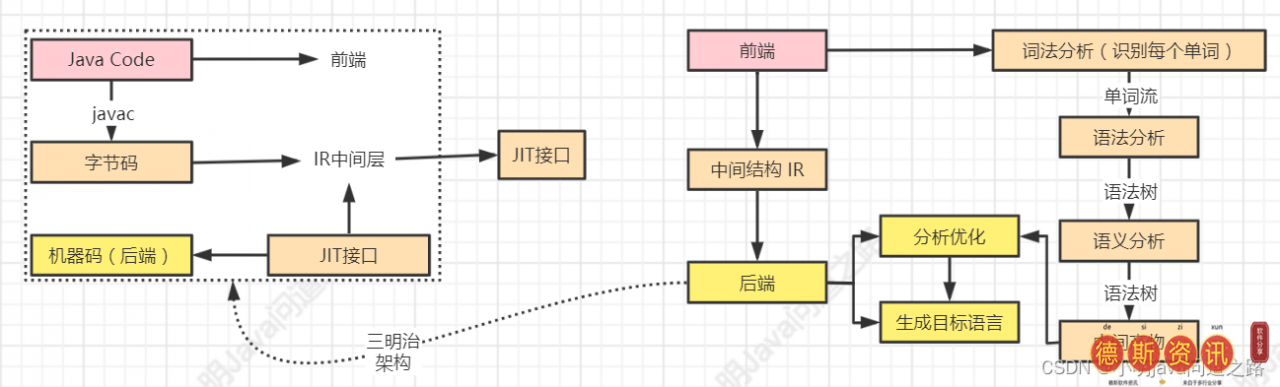
编译原理与Javac编译了解编译过程后,编译的目标语言叫汇编语言,它有两个编码规则,一个是at & T,指令形状是moveax1另一个是intel公司,指令形态是mov 1 eax(倒挂)。高级语言会被抽象成汇编语言;能否推导出指令段等价于一个函数;指令之间的调用(call instruction)类似于方法之间的调用(function call);而操作单元的大小抽象为type system(基本类型byte short int的存储单元为2 n (n >: =0),其他类型:structure(不同规则的存储单元),array(同类型的多个存储单元);数据地址操作被抽象为指针操作。